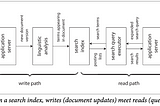
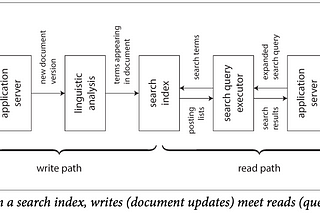
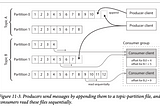
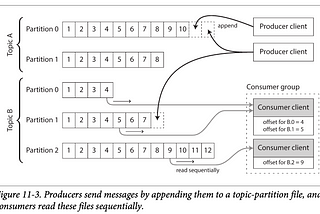
PinnedBook Report: Designing Data-Intensive ApplicationsThis is a summary of the book — Design Data Intensive Application by Martin Kleppmann. Below are the links to each chapter so as to keep…Jul 18, 2023Jul 18, 2023
PinnedBook Report: Design and Build Great Web APIsThis is a summary of the book — Design and Build Great Web APIs by Mike Amundsen. Below are the links to each chapter so as to keep it…Feb 25, 2022Feb 25, 2022
Chapter 12: The Future of Data SystemsSo far, this book has been mostly about describing things as they are at present. In this final chapter, we will shift our perspective…Aug 23, 2023Aug 23, 2023
Chapter 11: Stream processingOne big assumption we made throughout Chapter 10 was that the input is bounded — i.e., of a known and finite size — so the batch process…Jun 29, 2023Jun 29, 2023
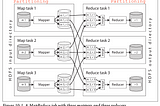
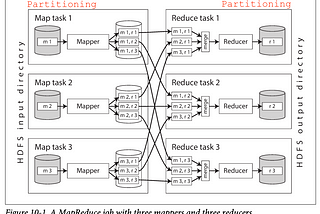
Chapter 10: Batch ProcessingOn a high level, systems that store and process data can be grouped into two broad categories:Jun 22, 2023Jun 22, 2023
Chapter 9: Consistency and ConsensusIn this chapter, we will talk about some examples of algorithms and protocols for building fault-tolerant distributed systems.Jun 14, 2023Jun 14, 2023
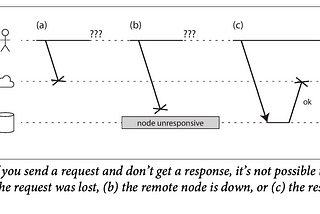
Chapter 8: The Trouble with Distributed SystemsA recurring theme in the last few chapters has been how systems handle things going wrong. For example, we discussed replica failover…Jun 12, 2023Jun 12, 2023
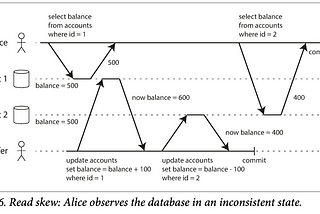
Chapter 7: TransactionsIn the harsh reality of data systems, many things can go wrong:May 9, 2023May 9, 2023
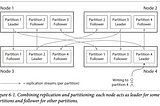
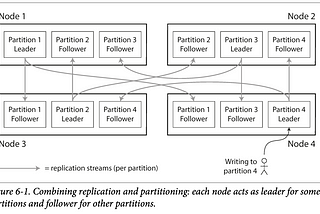
Chapter 6: PartitioningIn Chapter 5 we discussed replication — that is, having multiple copies of the same data on different nodes. For very large datasets, or…Apr 29, 20231Apr 29, 20231
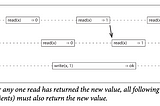
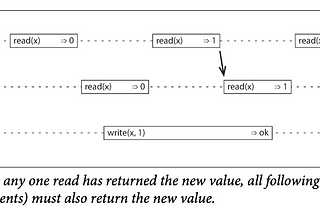
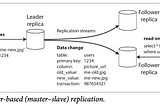
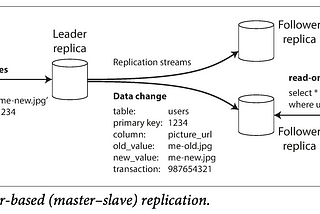
Chapter 5: ReplicationReplication means keeping a copy of the same data on multiple machines that are connected via a network. There are several reasons why you…Apr 23, 2023Apr 23, 2023